Transformers: Navigating the New Era of Attention in Technology
In 2017, a group of researchers (from Google and the University of Toronto) introduced a new way to handle natural language processing (NLP) tasks. Their revolutionary paper “Attention is All You Need” presented the Transformer model, an architecture that has since become the basis of many advanced AI systems today. The model’s performance, scalability, and versatility have led to its widespread adoption, forming the backbone of state-of-the-art models like BERT (Bidirectional Encoder Representations) and GPT (Generative Pre-trained Transformers).
Before the Transformer model, most AI models that processed language relied heavily on a type of neural network called a Recurrent Neural Network (RNN) or its improved version, the Long Short-Term Memory Network (LSTM). In particular, problems like language modeling and machine translation (also called sequence transduction). These models processed words in a sequence, one by one, from left to right (or vice versa). While this approach made sense because words in a sentence often depend on the previous words, it had some significant drawbacks:
Slow to Train: Since RNNs and LSTMs process one word at a time, training these models on large datasets was time-consuming.
Difficulty with Long Sentences: These models often struggled to understand relationships between words that were far apart in a sentence.
Limited Parallelization: Because the words were processed sequentially, it was hard to take advantage of modern computing hardware that thrives on doing many operations at once (parallelization).
The Key Idea: Attention To Architecture
The core idea behind the Transformer model is something called “attention.” In simple terms, attention helps the model to focus on specific parts of a sentence when trying to understand the meaning/context of a word. Consider the sentence, “The car that was parked in the garage is blue.” When you think about the word blue,” you naturally focus on the word “car” earlier in the sentence because it tells you what is blue. Machine translation models would struggle with identifying whether the “blue” was referring to the car or the garage. This is what self-attention does – it helps the model focus on the relevant words, no matter where they are in the sentence.
Note that attention wasn’t a new concept and was already being used in tandem with RNNs. Transformer was the first transduction model that relied solely on attention, thereby eliminating the need for neural networks. This gave the following advantages:
Parallel Processing: Unlike RNNs, which process words one after another, the Transformer can process all words in a sentence at the same time. This makes training much faster.
Better Understanding of Context: Because of the self-attention mechanism, the Transformer can capture relationships between words no matter how far apart they are in a sentence. This is crucial for understanding complex sentences.
Scalability: The model can be scaled up easily by adding more layers, allowing it to handle very large datasets and complex tasks.
As you can see, the new model not only removed all the disadvantages of neural networks but actually improved the performance of machine translation as well!
Since the original paper can be a little hard to understand, here is a simpler explanation of the model architecture described in the paper.
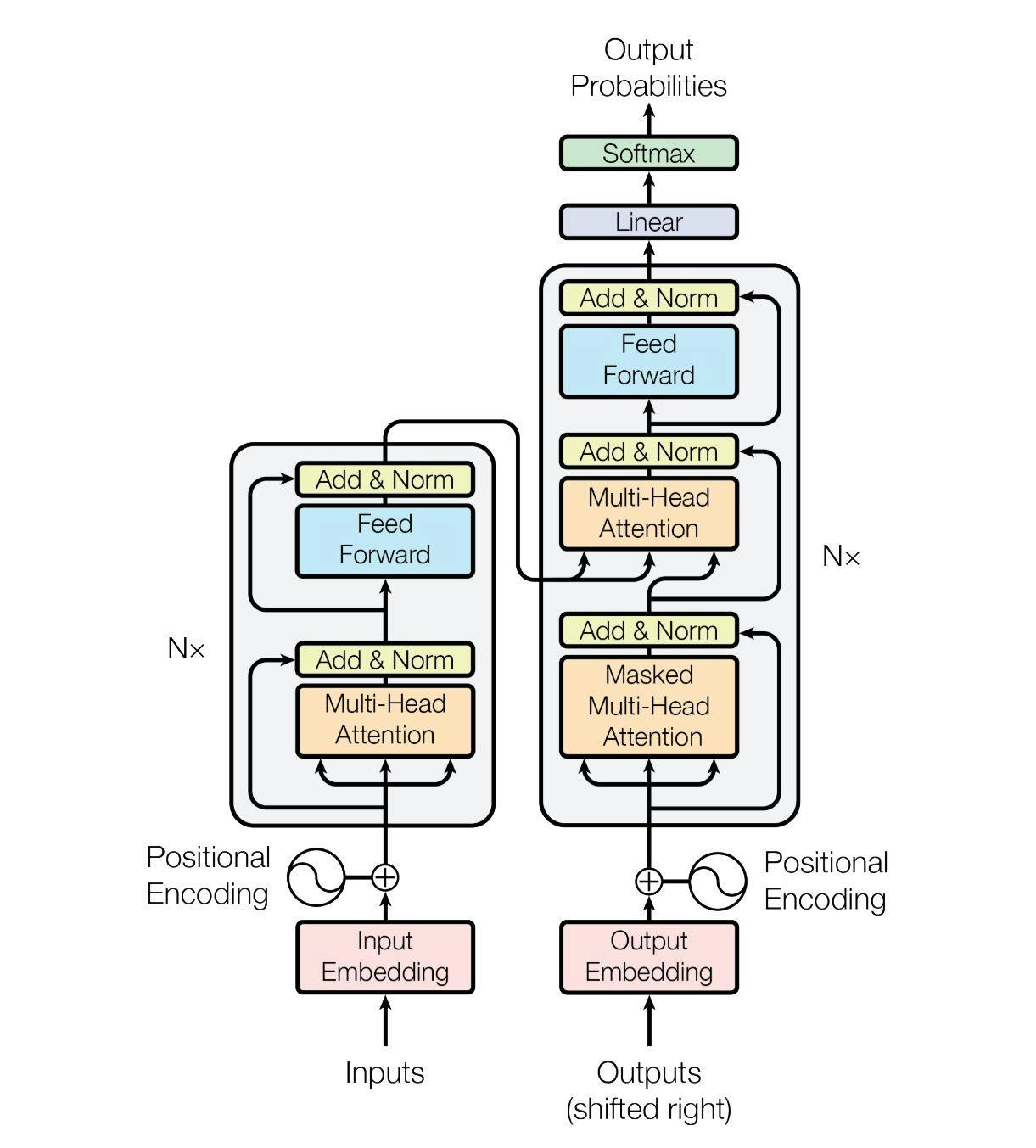
The Transformer – Model Architecture
Encoder and Decoder Stacks: The Transformer consists of an encoder stack (on the left) and a decoder stack (on the right). The encoder stack converts the input sequence (like a sentence) into a set of continuous representations, while the decoder stack converts these representations into an output sequence (like a translation). For each stack, going from bottom to top, here are the core components of the model explained with an example.
Input Sentence Processing in the Encoder
Inputs: The text that you want to translate. eg. “The car that was parked in the garage is blue.”
Input Embedding: Converts words into fixed-length numerical representations (vectors) called embeddings. These embeddings capture the semantic meaning of words in a way that the model can understand. From our example:
“The” -> [0.9, -0.4, 0.2, …]
“car” -> [0.5, 0.1, -0.7, …]
“that” -> [-0.8, 0.2, 0.8, …]
and similarly for each word in the above sentence.
Positional Encoding: Since the model processes the input embeddings, which don’t have any ordering, it needs a way to understand the order of words in a sentence. Positional encoding adds this information about the position of each word in the sequence to its embedding.
“The” at position 1 might get adjusted to [0.9 + P1, -0.4 + P1, 0.2 + P1, …], where P1 represents the positional encoding for the first position, thus generating a new embedding that’s unique for position P1.
Self-Attention Mechanism: As described earlier, this allows the model to focus on different words in a sentence depending on the context. For each word, the self-attention mechanism calculates a score that represents how much focus should be given to other words when encoding the current word.
For the word “car,” the self-attention might determine that “parked,” “garage,” and “blue” are particularly relevant in understanding its context.
Multi-head attention: Novel part of the transformer model. Multi-head attention is simply multiple self-attention layers/operations running in parallel and concatenated linearly.
For instance, one head might focus on the main subject (“car”) and its properties (“blue”), while another head might focus on the relative clause (“that was parked in the garage”).
The multi head attention module gives the model the capability to understand that “blue” is more relevant to the car compared to garage.
Feed-Forward Neural Networks: After the self-attention layer, the output is passed through a feed-forward neural network which is applied to each position separately and identically (once again, can be run in parallel!). This consists of two linear transformations with a ReLU activation in between.
Add & Norm: Residual connections (add) are used to add the input of a layer to its output, which is then normalized (norm). This helps with training deep networks by preventing gradients from vanishing or exploding.
Generating the Translation in the DecoderIn NLP, it’s common to denote the start of the start-of-sequence token with the special character and the end of the sequence with . The decoder takes the processed input from the encoder and generates the French translation “La voiture qui était garée dans le garage est bleue.” Here’s how this part works:
Input to the Decoder: The decoder begins with the encoded representation of the English sentence fron the encoder. If you notice, the decoder also takes its own output as input. Since it won’t have an input for the initial word, we insert <SOS> token at the start (hence shifted right) and remove the last word. This shifted sequence is what is fed into the decoder.
Masked Self-Attention: In the decoder, a masked self-attention mechanism ensures that each word in the output sequence can only attend to words before it. This prevents the model from looking ahead and ensures it generates the translation one word at a time from left to right.
For example, when the decoder is about to generate the word “La” (the first word in French), it only knows the context from <SOS> and not the future words like “Voiture.”
Feed-Forward Neural Networks: The decoder applies another feed-forward neural network to process this information further, refining the translation step-by-step.
In the decoder, after processing the input sentence through multiple layers of masked self-attention, encoder-decoder attention, and feed-forward networks, we obtain a sequence of continuous representations (vector of floats) for each position in the target sentence (French in our case). These representations need to be converted into actual words. This is where the final linear and softmax layer comes into play.
Linear Layer: This layer is a fully connected neural network layer that transforms the output of the last decoder layer (a dense vector representation for each position) into a vector the size of the target vocabulary (all possible words in the French language, for example).
Softmax Layer: After the linear transformation, a softmax function is applied to convert these logits (raw scores) into probabilities. These probabilities indicate the likelihood of each word in the target vocabulary being the correct next word in the translation. This enables us to guess which word from the French vocabulary should be selected (the cell with the highest probability).
The decoder essentially does this:
First Step: The decoder starts with <SOS> and generates the first word “La.”
Second Step: With the input <SOS> La, the model predicts the next word, “Voiture.”
Third Step: The decoder takes <SOS> La Voiture and generates the word “quit.”
Continuing Process: This process continues, generating “était,” “garée,” “dans,” “le,” “garage,” “est,” and finally “bleue.”
End-of-Sequence Token: The decoder eventually generates an end-of-sequence token <EOS> to signify that the translation is complete.
By combining these steps, the Transformer can understand the entire sentence’s structure and meaning more effectively than previous models. The self-attention mechanism and parallel processing enable the Transformer to effectively capture the nuances and structure of both the source and target languages, making it highly proficient at tasks like machine translation.
This article was originally published by Bhavdeep Sethi on HackerNoon.
{kind=link}