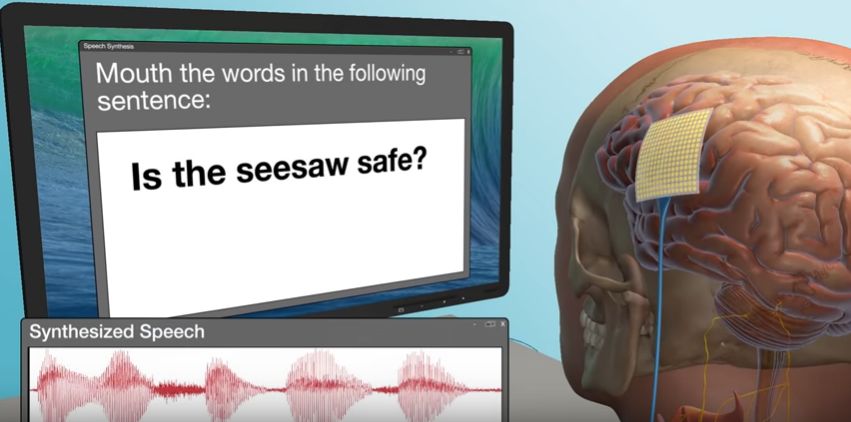
Neuroscientists at University College San Francisco (UCSF) have created a brain-computer interface that can generate speech through brain activity. It is one of the latest developments in the synthetic speech domain and is among a growing number of use cases.
“For the first time, this study demonstrates that we can generate entire spoken sentences based on an individual’s brain activity”
Read More: Brain-computer interface helps turn brainwave patterns into speech
Whilst the study involved research participants with intact speech, it is hoped that this breakthrough will lead to the restoration of speech for patients who have lost their ability to speak as a consequence of various forms of neurological damage.
This would be a major advance on current technology. Presently, the best alternative for speech-disabled people is the use of devices that monitor eye or facial muscle movements. However, this approach facilitates 10 words per minute at best. Natural speech implicates 100 to 150 words per minute.
In a statement published to the UCSF website, senior author of the study Edward Chang said:
“For the first time, this study demonstrates that we can generate entire spoken sentences based on an individual’s brain activity. This is an exhilarating proof of principle that with technology that is already within reach, we should be able to build a device that is clinically viable in patients with speech loss.”
The research team has been working on this subject area for some time. The study builds upon a previous study in 2018. That study revealed brain activity patterns underlying fluent speech.
Synthetic Speech Research
The team at UCSF is one of many working on the subject area. Dr. Nima Mesgarani of Colombia University’s Zukerman Institute led a team which recently announced that a brain-computer interface had been utilized in order to turn brainwave patterns into speech.
Read More: Brain-computer interface allows for telepathic piloting of drones
In both cases, epilepsy patients have been used as the focal point for each study. As epilepsy patients need to undergo brain surgery, this provides the opportunity for researchers to also investigate speech synthesis.

Stephen Hawking, Stockholm in 2015. Image courtesy of Wikimedia.
In the case of Dr. Mesgarani’s research, a robotic sounding voice was output. The same is true in the instance of the UCSF research. However, its understood that their findings are such that they believe there will be an opportunity in the future to make the speech output more authentic.
This would have been beneficial to the brilliant physicist and cosmologist, Stephen Hawking. Hawking – who passed away in 2018 – used a very robotic sounding speech generation device to speak.
Hawking’s motor neuron disease prevented him from talking – necessitating a digital device in an effort to facilitate communication.
Google is soon likely to unveil Project Euphonia with an objective of leveraging its existing technologies to give people with speech impediments their voice back.
Broader Voice Synthesis Context Brings Greater Use Cases
The area of synthetic speech is of interest from a number of perspectives. It’s usefulness extends beyond the goal of bringing speech to the vocally challenged. Synthetic speech is also very much of relevance when it comes to text to speech (TTS) technology.
Devices such as GPS voice navigation systems, Google Home and Amazon Alexa – together with translation applications such as Google Translate, have become increasingly important in recent years.
Daisy Stanton, Software Engineer with Google AI, spoke to the importance of text to speech technology via a recent blog post:
“TTS opens up the internet to millions of users all over the world who may not be able to read, or who have visual impairments.”
Stanton clarifies that there has been a significant increase in research into human voice simulation using artificial intelligence (AI) in recent times. As with all technology however, it can be used progressively or otherwise. The Google engineer warns that bad actors are also using synthetic speech to outsmart voice recognition systems.
Read More: Is there nothing that can’t be faked with vocal, facial manipulation?
TTS is not a finished technology. Research is ongoing and as recently as last week, a study on the subject was published by a team within Amazon’s Alexa division. That study points towards performance improvements as a result of switching to a neural based TTS system. This AI based approach is resulting in more natural sounding speech, with less words being dropped.
The application of TTS technology continues to grow. It is playing a role in education – particularly when it comes to the education of students with dyslexia. Voice enabled virtual assistants and chatbots are likely to be utlized across multiple industry verticals. Globally, the speech and voice recognition market is expected to have a value of $32 billion by 2025.
Meanwhile, for the vocally challenged, the UCSF research is encouraging. However, it’s unlikely to be developed to a finished product for quite some time yet.
“We still have a ways to go to perfectly mimic spoken language”, acknowledged Josh Chartier – a leading researcher on the UCSF study. “Still, the levels of accuracy we produced here would be an amazing improvement in real-time communication compared to what’s currently available.”