


Winter(Physics) is Coming
It now looks like Large Language Models running on the GPT technology may be nearing a plateau in their development. This is from popular Physicist Dr. Sabine Hossenfelder’s latest YouTube video.
Dr. Sabine cites a couple of sources, including Bill Gates, who said last year that GPT 5 won’t be much better than GPT 4. And Prof. Gary Marcus says he has been drumming this particular beat for years. This goes against all the Ray Kurzweilian hype by Sam Altman and Ilya Sutskever as seen in the video.
But if merely beautiful mathematics won’t spur the progress of Physics, as Dr. Sabine always reminds us, then merely wishful group-thinking won’t give us a superhuman artificial general intelligence (AGI).

Now I think there is a big wall. (Source – https://x.com/sama/status/1856941766915641580)
Why isn’t throwing as much data, computing power, and human supervision as can be afforded, going to birth us a superhuman AGI?
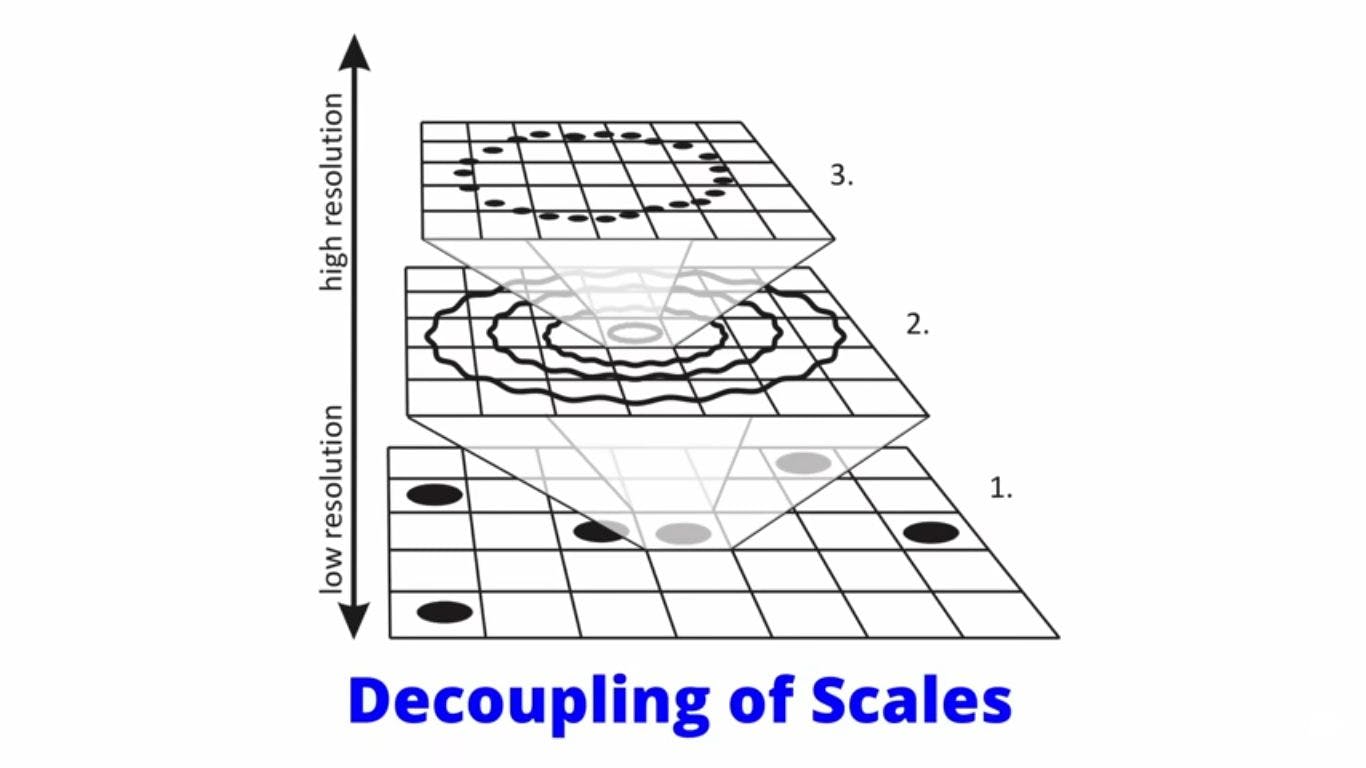
Dr. Sabine has a ready answer. The problem, she explains, is the Decoupling of Scales.
The Decoupling of Scales
The world is broken up into scales.
In the physical world, there is the scale of land animals like us humans. Then below that we have microbes, then molecules, atoms, and subatomic particles. In the opposite direction, we have aircraft and skyscrapers, mountains, planets, stars, solar systems, galaxies, etc.

As we go farther down, reality looks different across scales so that we cannot infer the bottom from the top. And vice versa.
In the world of data, we have high-resolution data e.g. categories like “objects that can be touched”, “animals”, “cats”. Then low-resolution data to further expand the above categories e.g. “cat species”, “cat patterns”, “cat behavior at 8:00 am on Monday,” etc.
There are other taxonomies, however. Some data is online and some is offline in books, papers, and people’s minds.
We may have all the knowledge we desire at the high-resolution scale of human language creation on the internet. But that doesn’t equate to the much bigger, low-resolution data source that is human language creation in the world.
Thus, Sam Altman’s AI is like Aristotle in the image below. Hoping to discover the Standard Model of Physics by looking at his hand.

This doesn’t work
But without something like the Large Hadron Collider to poke subatomic particles and see the strange new data hiding within, Aristotle is at a loss on how to proceed.

A Large Hadron Collider for AI
GPT architecture, unveiled to the world only 2 years ago with the phenomenal ChatGPT, is likely nearing the end of its “improvement-ness”. Perhaps it is time to seriously consider passing the baton, and the VC funding, to something else.
I am rooting for thermodynamic computing, currently being explored by companies like Extropic, which works by leveraging thermal noise to create random samples of data as in Stable Diffusion technology, then denoising using statistical analysis.
In fact, in any neural network, the initial weights are usually initialized with random noise. During training, backpropagation shapes the final weights from this random noise – writes Laszlo Fazekas.
The advantage lies in the chips operating at scales smaller than those of traditional digital computing, where quantum effects result in abundant thermal noise.
Thermal noise has always been plenty, anyway.
My kitchen stove is full of thermal noise.
The real problem has always been how to understand it better through statistical chunking of its data, without throwing away data during regression analysis.
My guess? Some sort of massive cloud computational AI training leveraging smartphones, bitcoin nodes, TV sets, radios, name it.
Currently, allowing the AI some “thinking time’“ so that it runs longer inferences on the same data, is how AI companies are squeezing out some more juice. For example with ChatGPT’s o1 model.
But maybe even training time should be extended. Maybe to get great AI, like a child, it needs decades of training from data collected from all over. Collected and slowly siphoned into a condensed AI model in a few servers.
Sam Altman might need those trillions of government dollars for such a plan. Alas, they will likely not be easy to get. The D.O.G.E might not bankroll him (if xAI is suffering the same troubles).
Meanwhile, Bitcoin is still growing

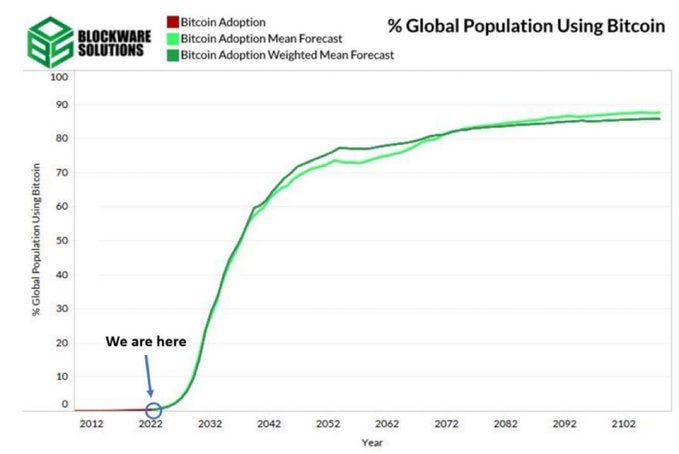
Blockware Solutions Graph: % of global popluation using Bitcoin
As the above graphic shows, very few people are using Bitcoin. Yet it is already at $90k.
Data from Bitbo shows that in fact, only 400,000 people are using Bitcoin daily. And only 106 million own Bitcoin.
Contrast this with the 314 million people who have used AI tools as per data from Statista. ChatGPT alone has millions of users per day. Probably more than the entire Bitcoin blockchain combined!
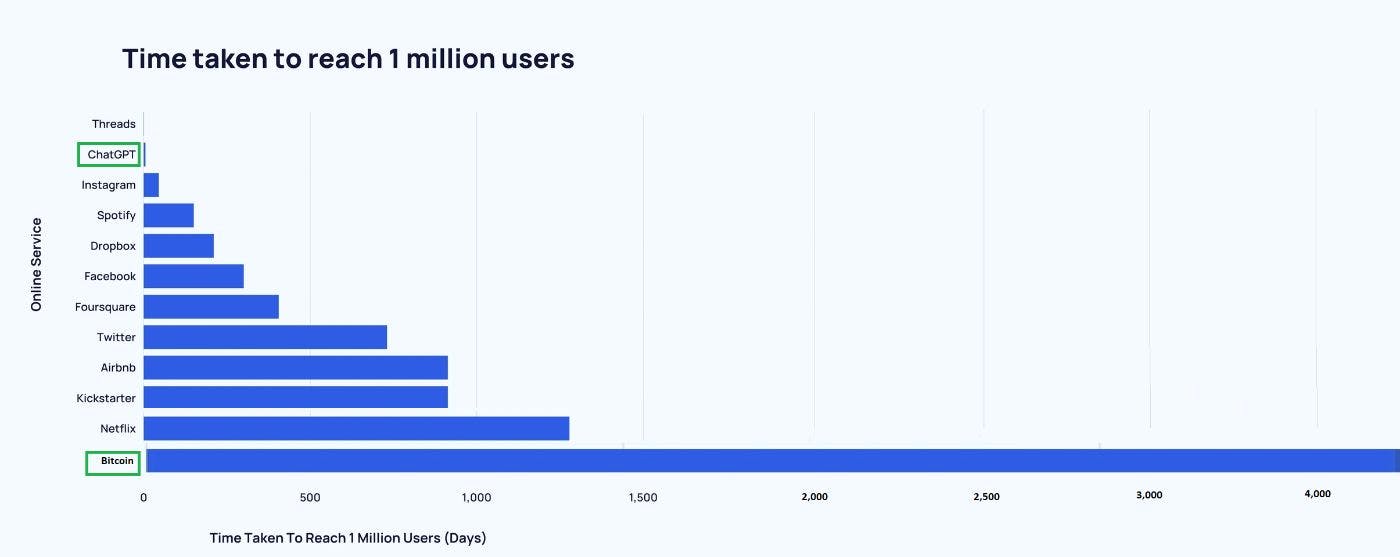
What’s more? AI amassed the bulk of these users in less than a year. This feels wrong. Bitcoin took years to grow. People sweated, lost, DCA’d, had faith.
Maybe that’s it. ChatGPT has grown too fast. Now it has slowed down and everybody is sour.
Sorry, ya’ll, there is still work to do. AGI will not be so easy to grasp, and GPT scientists should learn to hodl like Bitcoiners. Winter will come and go, but right now, it is time to pay the piper.

Bitcoin took years while ChatGPT took days to get 1 million users.
This article was originally published by M-Marvin Ken on HackerNoon.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}