


IARPA awards a research contract for extracting data from text to Raytheon BBN, which harvests the text of social media postings and other data.
“An opportunity to develop better methods to extract complex semantic information from documents”
The Intelligence Advanced Research Projects Activity (IARPA) has awarded contracts for its Better Extraction from Text Towards Enhanced Retrieval (BETTER) program.
Among those rewarded contracts last week were several universities including Johns Hopkins University, Brown University, and the University of Southern California Information Sciences Institute, but also, Raytheon BBN.
Raytheon has been a valuable asset to the intelligence community for many, many years, and it is a company that has its hands in just about every technology suited for “defense, civil government and cybersecurity solutions.”
Through its multimedia monitoring system (M3S), Raytheon scours the internet to make sense of data in multiple languages, so it can be easily digested by analysts.
“M3S not only harvests the text of social media postings, but also gathers metadata such as geotags, hashtags, user references, URLs, topic threading information and retweet information.”
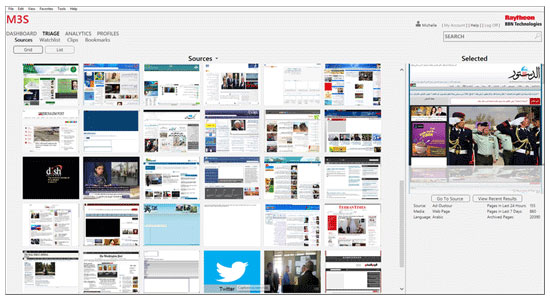
Raytheon BBN M3S screenshot
“Using this information, the system can accurately reconstruct interactions across networks, setting the stage for social media analytics,” according to the Raytheon website.
One of Raytheon’s specialties is in collecting data from social media platforms such as Facebook, YouTube, and Twitter.
Some of Raytheon’s M3S services include:
- Automatic multi-lingual data collection and mirroring of user-identified Web sites, broadcast media, and social media (Twitter and Facebook)
- Automatic extraction and translation of text
- Search across multi-lingual sites, channels, and posts
- Visualization tools and automatic topic detection for enhanced analysis
- Collected media archived for later use
- Story segmentation of broadcast media
- Designed for inter-agency data sharing
- Effective retrieval and triage for human analysts who must deal with overwhelming volumes of continuously accumulating media.
IARPA finds these qualities useful in its mission “to tackle some of the most difficult challenges of the agencies and disciplines in the intelligence community.”
“There’s too much for any one individual person to read or any team of people to read on a given day”
What Raytheon’s M3S does is almost verbatim what IARPA said it was looking for when it held a proposers’ day on March 29, 2018.
The goal of the BETTER program is “to provide a user [analyst] with a system that quickly and accurately extracts complex semantic information, targeted for a specific user, from text. The system then uses this extracted information to discover and triage relevant documents from a large corpus.”
As I see it, IARPA wants to:
- Extract data from mountains of text written in multiple languages (sources could be from news media, social media, websites, etc.)
- Organize and personalize that data, so it is catered to specific needs of the analyst
- Recommend other documents to analyze that are relevant to the analyst’s interests
At the proposer’s day (above video) IARPA program manager Dr. John Beieler explained the problem the intelligence community was looking to solve.
“#SpoilerAlert! We’re re-ranking document lists”

John Beieler
“There’s constantly more text that’s being generated. There’s too much for any one individual person to read or probably any team of people to read on a given day.”
“A lot of times this stuff comes across in multiple languages. If you’re trying to look at all the news that was published across the world yesterday — multiple languages — too much.
“Then this concept of finding orthogonal information when you’re trying to discover something, it’s kind of like looking for your keys on a dark night under the streetlight.
“You’re kind of looking in this one place, but really they’re probably somewhere else.”
The solution, according to Dr. Beieler, is an automated process that analyzes a ton of text and makes recommendations on where to look next.
“Hashtag ‘Spoiler Alert!’ we’re re-ranking document lists […] We’re re-ranking documents based on relevancy.”
“What we’re really trying to do is smash together information extraction, information retrieval, and active learning”
The BETTER program will look to exploit machine learning technology and because of this foreign language expertise will be disallowed.
“How we envision the technology in this program is to provide automated suggestions and provide the most relevant documents — a kind of a recommender system (i.e. ‘you read this, maybe you want to read this’) and then automatically tag information according to that individual analyst’s knowledge,” the BETTER program manager said.
He added, “What we’re really trying to do is smash together information extraction, information retrieval, and active learning to enable this downstream use of extraction and retrieval of fine-grain personalized knowledge.
“We’re doing things across languages and we’re doing things for an individual rather than these kind of overarching ‘one ontology to rule them all’ approaches.
According to Beieler, IARPA’s BETTER program “gives us an opportunity to develop better methods to extract complex semantic information from documents and then to use this extracted semantic information to do basically document triage.”







